import pandas as pd
import nltk
import matplotlib.pyplot as plt
import ipywidgets
import gensim
import re
import wordcloud
import altair
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from string import punctuation
from nltk.stem.porter import PorterStemmer
from gensim import corpora, modelsIntroduction
If you are a movie fan, you might notice that in most movie recommendation websites, apart from the category the movie is classified in, there’s usually some descriptive tags attached to each movie. The tags can describe the character in the movie, such as The Dark Knight which has the “superhero” tag, or an element in the movie, like the tag “dinosaur” on Jurassic World. Sometimes, the tag could even be the name of a movie star, such as “Leonardo” on Titanic. From a perspective of a movie fan, it’s undoubtedly that these tags display the attractive points of the movie more vividly than the tedious classifications “Classic movies” and “Action movies”. Therefore, people began to extract tags from the content of the films, utilizing machine learning and natural language processing methods.
This project is aimed to explore a Netflix movies dataset, to gain some insights about movie industry and make an attempt to extract some tags from the movie descriptions.
Methods
Dataset Introduction
This notebook includes a movie dataset from https://www.kaggle.com/datasets/shivamb/netflix-shows, which consists of listings of all the movies and TV-shows available on Netflix, along with details such as - cast, directors, ratings, release year, duration, etc.
Specifically, here’s the meaning of each column in the dataset:
show_id: Unique ID for every Movie / Tv Show
type: Identifier - A Movie or TV Show
title: Title of the Movie / Tv Show
director: Director of the Movie
cast: Actors involved in the movie / show
country: Country where the movie / show was produced
date_added: Date it was added on Netflix
release_year: Actual Release year of the move / show
rating: TV Rating of the movie / show
duration: Total Duration - in minutes or number of seasons
listed_in: Genere
description: The summary descriptionLDA model
Latent Dirichlet allocation (LDA) is a widey used topic-generating model. The model can identify the representative topics underlying a document collection or a corpus. This model produces topics based on bag-of-word feature, that each document is represented as a vector, in which every word corresponds to an id and its appearing frequency in the document. When producing the topics, The model samples a document-specific multinomial distribution over topics from Dirichlet distribution, and samples the word in the document from the corresponding multinomial distribution.
📊 Exploratory Analysis & Results
1. 🎥 Data Preprocessing
Import the libraries
Import the dataset and create a dataframe for movies
df = pd.read_csv("data/netflix_titles.csv")
movies = df[df["type"]=="Movie"]
movies.index = range(len(movies))Column information
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6131 entries, 0 to 6130
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 show_id 6131 non-null object
1 type 6131 non-null object
2 title 6131 non-null object
3 director 5943 non-null object
4 cast 5656 non-null object
5 country 5691 non-null object
6 date_added 6131 non-null object
7 release_year 6131 non-null int64
8 rating 6129 non-null object
9 duration 6128 non-null object
10 listed_in 6131 non-null object
11 description 6131 non-null object
dtypes: int64(1), object(11)
memory usage: 574.9+ KBMissing values visualization
<AxesSubplot:>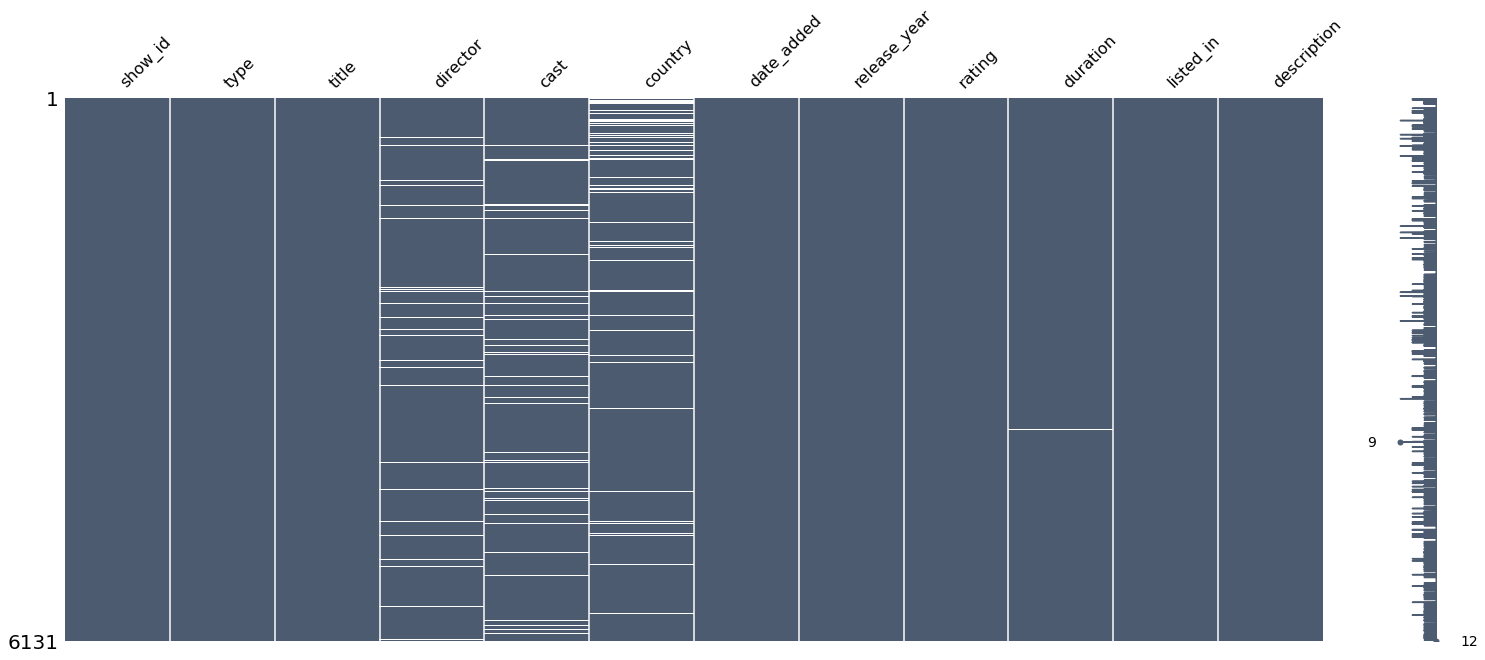
🍿️Comment: - The missing values are distributed in columns “director”, “cast”, “country” and “duration”.
Sample rows
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2227 | s3449 | Movie | Brother in Love | Onur Bilgetay | Cem Gelinoğlu, Melis Babadag, Ege Kökenli, Müf... | Turkey | October 4, 2019 | 2019 | TV-MA | 110 min | Comedies, International Movies, Romantic Movies | A robbery leaves a proprietor penniless before... |
| 4570 | s6849 | Movie | Ghost Tears | Kazuchika Kise | Maaya Sakamoto, Ikkyu Juku, Kenichirou Matsuda... | Japan | February 24, 2019 | 2014 | TV-MA | 58 min | Action & Adventure, Anime Features, Internatio... | As Motoko and Batou attempt to thwart a myster... |
| 3034 | s4740 | Movie | Being Napoleon | Jesse Handsher, Olivier Roland | Mark Schneider, Frank Samson | United States | August 1, 2018 | 2018 | TV-MA | 88 min | Documentaries | On the 200th anniversary of the Battle of Wate... |
| 2129 | s3281 | Movie | The Garden of Words | Makoto Shinkai | Miyu Irino, Kana Hanazawa, Fumi Hirano, Takesh... | Japan | November 15, 2019 | 2013 | TV-14 | 46 min | Anime Features, International Movies, Romantic... | When a lonely teenager skips his morning class... |
| 5231 | s7687 | Movie | Outlawed | Adam Collins, Luke Radford | Adam Collins, Jessica Norris, Ian Hitchens, St... | United Kingdom | February 15, 2019 | 2018 | TV-MA | 102 min | Action & Adventure | After a failed mission, an ex-Royal Marines Co... |
🍿️Comment: - Based on the information in these rows, I converted the values in “duration” column into integers and the values in “date_added” column into date, to prepare them for plotting in the next section.
2. 📈Exploratory Analysis
Visualization 1
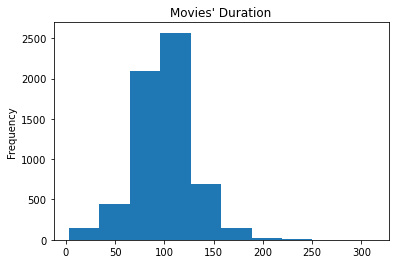
🍿️Comment: - The histogram shows that most movies on Netflix are about 100 minutes. The longest movie contained in this dataframe is about to reach 300 minutes, nearly 5 hours.
Visualization 2
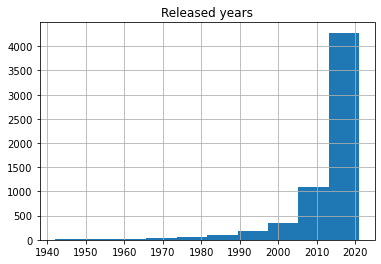
🍿️Comment: - Most movies included in the dataframe are released in recent 10 years.
Visualization 3
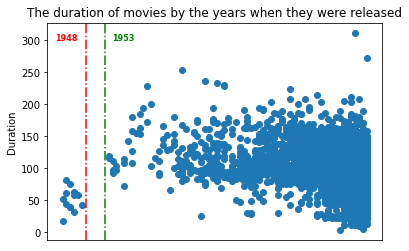
🍿️Comments: - There’s blank area between 1948 and 1953. - The duration of all movies shot before 1948 are below 100 minutes. - There’s an increase of movies duration after 1953, that most movies’ duration surpass 100 minutes and the longest one even reaches 200 minutes. - The short movies didn’t quit the stage. In recent 10 years, there are still many movies with the duration below 50 minutes.
Visualization 4
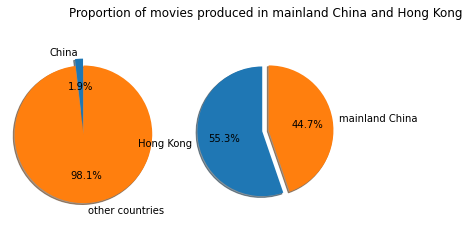
🍿️Comment: - Few films produced in mainland China are available on Netflix. The number of movies on Netflix produced in Hong Kong even surpasses that of mainland China.
Visualization 5
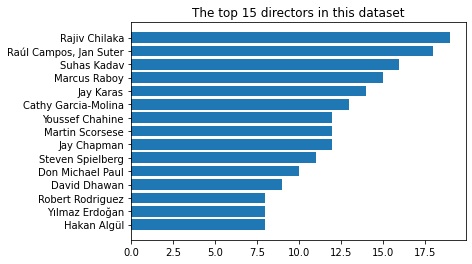
🍿️Comment: - There are many renowned directors such as “Christopher Nolan” and “Alfred Hitchcock” who have directed many well-known movies are not included, from which it’s reasonable to infer that many popular movies aren’t available on Netflix or they didn’t be collected by this dataset.
Visualization 6
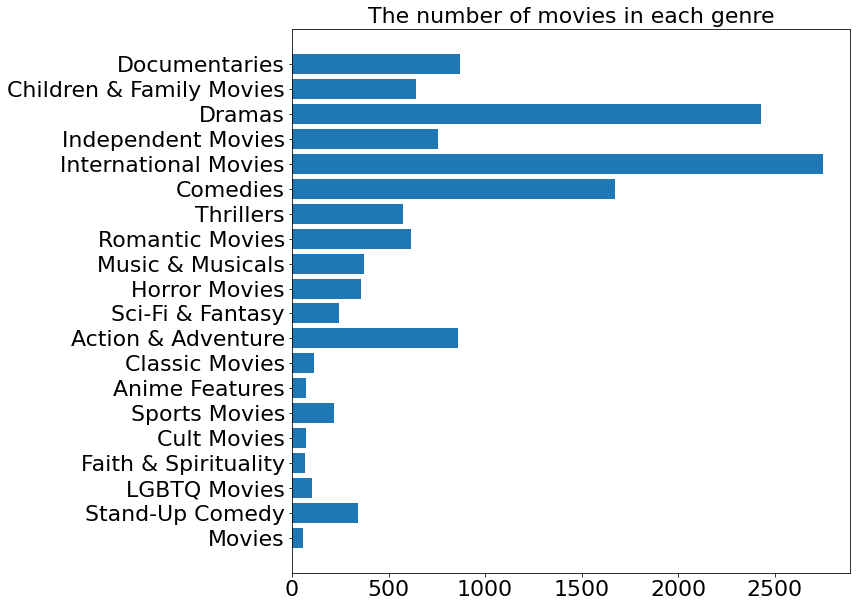
🍿️Comments: - Apart from those movies that have been clearly categorized, there’s a type named “Movies”, which suggests that movies in this type are not categorized due to some reason. We will examine the content of these movies and determine how should they be classified. - There aren’t clear boundary between some of the categories, which means a movie can have multiple categories. The dim boundary may confuse the viewers and thus it’s necessary to give these movies representative tags. - Through the names of some categories we can roughly predict the content of the movies. For instance, Faith & Spirituality movies may contain a lot of religious elements. This provides the possibility for the afterwards tag prediction task based on the descriptions of movies.
3. 🏷 Tags Extraction
In this section, I used the LDA model to analyze the descriptions of a certain category of movie and extract the keywords to represent the category. Specifically, I first used nltk to preprocess the description texts. Then I made a dictionary and a corpus for the tokenized and stemmed words. Finally, I used the LDA model to extract the keywords depending on appearing frequency and drew the word cloud graph to visualize the result.
Create a list to store the descriptions of movies from different categories
# Create a list to store the descriptions of movies from different categories.
DescByTypes = []
for i in range(len(categories)):
DescByTypes.append([movies.loc[x,'description'] for x in range(len(movies)) if categories[i] in movies.loc[x,'listed_in'].split(', ')])Create the list for documentary descriptions
# First try to predict some tags for Documentaries.
Documentaries = DescByTypes[0]Tokenize the document
# Create a list for tokenized words and remove those stop words.
myStopWords = list(punctuation) + stopwords.words('english')
Docu = []
for i in Documentaries:
Docu.append([w for w in word_tokenize(i.lower()) if w not in myStopWords])Stem the words
# Stem the words in this list.
p_stemmer = PorterStemmer()
Docu_stemmed = []
for i in Docu:
Docu_stemmed.append([p_stemmer.stem(w) for w in i])Create a dictionary
# Create a dictionary for this document.
dictionary = corpora.Dictionary(Docu_stemmed)
dictionary.filter_extremes(no_below=5, no_above=0.5)#collapse-output
print(dictionary.token2id){'comic': 0, 'death': 1, 'end': 2, 'face': 3, 'father': 4, 'filmmak': 5, 'help': 6, 'life': 7, 'stage': 8, 'way': 9, 'becam': 10, 'close': 11, 'document': 12, 'escap': 13, 'hitler': 14, 'presid': 15, 'reveal': 16, 'spain': 17, 'world': 18, "'s": 19, 'big': 20, 'childhood': 21, 'dream': 22, 'live': 23, 'love': 24, 'rescu': 25, 'train': 26, 'archiv': 27, 'champion': 28, 'documentari': 29, 'footag': 30, 'interview': 31, 'intim': 32, 'michael': 33, 'portrait': 34, 'trace': 35, 'bond': 36, 'extraordinari': 37, 'ideal': 38, 'meet': 39, 'tragic': 40, 'captur': 41, 'killer': 42, 'mother': 43, 'polic': 44, 'two': 45, 'victim': 46, 'women': 47, 'work': 48, 'chart': 49, 'legendari': 50, 'man': 51, 'stori': 52, 'use': 53, 'american': 54, 'challeng': 55, 'chang': 56, 'continu': 57, 'health': 58, 'tradit': 59, 'win': 60, 'gener': 61, 'last': 62, 'peopl': 63, 'togeth': 64, 'cultur': 65, 'examin': 66, 'famili': 67, 'hip-hop': 68, 'perform': 69, 'race': 70, 'rap': 71, 'song': 72, 'violenc': 73, "''": 74, '``': 75, 'advoc': 76, 'inspir': 77, 'intern': 78, 'relationship': 79, 'share': 80, 'star': 81, 'tour': 82, 'view': 83, 'boy': 84, 'run': 85, 'team': 86, '—': 87, 'art': 88, 'battl': 89, 'bob': 90, 'busi': 91, 'cast': 92, 'empir': 93, 'famou': 94, 'joy': 95, 'million': 96, '’': 97, 'becom': 98, 'first': 99, 'four': 100, 'river': 101, 'set': 102, 'come': 103, 'connect': 104, 'featur': 105, 'greatest': 106, 'human': 107, 'journey': 108, 'power': 109, 'rock': 110, 'embrac': 111, 'even': 112, 'olymp': 113, 'path': 114, 'road': 115, 'true': 116, 'crime': 117, 'narrat': 118, 'record': 119, 'seri': 120, 'abus': 121, 'martin': 122, 'person': 123, 'public': 124, 'girl': 125, 'discuss': 126, 'fan': 127, 'fight': 128, 'figur': 129, 'game': 130, 'legaci': 131, 'nba': 132, 'player': 133, 'brazilian': 134, 'citi': 135, 'crew': 136, 'decad': 137, 'film': 138, 'find': 139, 'took': 140, 'creat': 141, 'pioneer': 142, 'privat': 143, 'queen': 144, 'struggl': 145, 'commun': 146, 'devast': 147, 'movement': 148, 'speak': 149, 'survivor': 150, 'drug': 151, 'onlin': 152, 'career': 153, 'decades-long': 154, 'glimps': 155, 'delv': 156, 'call': 157, 'femal': 158, 'offic': 159, 'pay': 160, 'sexual': 161, 'album': 162, 'bring': 163, 'hit': 164, 'rapper': 165, 'camp': 166, 'championship': 167, 'compet': 168, 'emerg': 169, 'teen': 170, 'actress': 171, 'deep': 172, 'eye': 173, 'hollywood': 174, 'look': 175, 'take': 176, 'dive': 177, 'journalist': 178, 'mexican': 179, 'murder': 180, 'polit': 181, 'day': 182, 'follow': 183, 'footbal': 184, 'risk': 185, 'time': 186, 'around': 187, 'comedian': 188, 'men': 189, 'passion': 190, 'street': 191, 'final': 192, 'friend': 193, 'high': 194, 'school': 195, 'suicid': 196, 'creativ': 197, 'design': 198, 'director': 199, 'goe': 200, 'origin': 201, 'search': 202, 'age': 203, 'competit': 204, 'pursu': 205, 'sister': 206, 'three': 207, 'track': 208, 'truth': 209, 'adventur': 210, 'best': 211, 'build': 212, 'uniqu': 213, 'comedi': 214, 'experi': 215, 'free': 216, 'side': 217, 'war': 218, 'special': 219, 'chronicl': 220, 'larg': 221, 'member': 222, 'base': 223, 'divers': 224, 'emot': 225, 'five': 226, 'fuel': 227, 'young': 228, "'ve": 229, 'lead': 230, 'make': 231, 'new': 232, 'open': 233, 'scientist': 234, 'anim': 235, 'begin': 236, 'creator': 237, 'celebr': 238, 'home': 239, 'moment': 240, 'present': 241, 'showcas': 242, 'video': 243, 'crisi': 244, 'david': 245, 'earth': 246, 'known': 247, 'one': 248, 'prepar': 249, 'singer': 250, 'black': 251, 'explor': 252, 'quest': 253, 'understand': 254, 'univers': 255, 'america': 256, 'prison': 257, 'system': 258, 'year': 259, 'bomb': 260, 'gay': 261, 'london': 262, 'effect': 263, 'evolut': 264, 'genr': 265, 'activist': 266, 'amid': 267, 'controversi': 268, 'earli': 269, 'justic': 270, 'right': 271, 'endur': 272, 'recount': 273, 'club': 274, 'past': 275, 'success': 276, 'writer': 277, 'artist': 278, 'concert': 279, 'music': 280, 'tell': 281, 'discov': 282, 'woman': 283, 'camera': 284, 'student': 285, 'turn': 286, 'fall': 287, 'industri': 288, 'john': 289, 'rise': 290, '1980': 291, 'band': 292, 'sound': 293, 'former': 294, 'india': 295, 'return': 296, 'profession': 297, 'indian': 298, 'product': 299, 'scene': 300, 'seen': 301, 'behind-the-scen': 302, 'provid': 303, 'root': 304, 'york': 305, 'talk': 306, 'trauma': 307, 'kill': 308, 'line': 309, 'media': 310, 'social': 311, 'icon': 312, 'memori': 313, 'investig': 314, 'research': 315, 'answer': 316, 'behind': 317, 'disappear': 318, 'mysteri': 319, 'expos': 320, 'role': 321, 'white': 322, 'complex': 323, 'offer': 324, 'beauti': 325, 'ident': 326, 'includ': 327, 'mean': 328, 'practic': 329, 'spiritu': 330, 'ii': 331, 'corrupt': 332, 'global': 333, 'ocean': 334, 'belov': 335, 'walk': 336, 'get': 337, 'rich': 338, 'top': 339, 'us': 340, 'real': 341, 'fashion': 342, 'in-depth': 343, 'king': 344, 'notori': 345, 'rare': 346, 'air': 347, 'hous': 348, 'innov': 349, 'brazil': 350, 'hero': 351, 'nation': 352, 'talent': 353, 'turbul': 354, 'mix': 355, 'back': 356, 'countri': 357, 'land': 358, 'natur': 359, 'ground': 360, 'physic': 361, 'question': 362, 'seek': 363, 'group': 364, 'start': 365, 'danc': 366, 'effort': 367, 'program': 368, 'globe': 369, 'visual': 370, 'idol': 371, 'italian': 372, 'short': 373, 'strength': 374, 'histori': 375, 'charact': 376, 'backstag': 377, 'basketbal': 378, 'determin': 379, 'french': 380, 'led': 381, 'whose': 382, 'go': 383, 'scienc': 384, 'process': 385, 'spark': 386, 'play': 387, 'actor': 388, 'ambiti': 389, 'six': 390, 'chef': 391, 'embark': 392, 'reflect': 393, 'restaur': 394, 'spotlight': 395, 'cours': 396, 'futur': 397, 'brown': 398, 'leader': 399, 'children': 400, 'forg': 401, 'societi': 402, 'throughout': 403, 'hope': 404, 'south': 405, 'tri': 406, 'need': 407, 'shape': 408, 'award-win': 409, 'de': 410, 'la': 411, 'attempt': 412, 'unearth': 413, '1970': 414, 'strive': 415, 'mission': 416, 'save': 417, 'across': 418, 'water': 419, 'forc': 420, 'leav': 421, 'trip': 422, 'child': 423, 'detail': 424, 'daughter': 425, 'fail': 426, 'mexico': 427, 'join': 428, 'major': 429, 'superstar': 430, 'move': 431, 'insid': 432, 'influenti': 433, 'immigr': 434, 'event': 435, 'center': 436, 'differ': 437, 'africa': 438, 'african': 439, 'introduc': 440, 'combat': 441, 'expert': 442, 'may': 443, '1992': 444, 'danger': 445, 'impact': 446, 'learn': 447, 'light': 448, 'shed': 449, 'pop': 450, 'account': 451, 'domin': 452, 'athlet': 453, 'elit': 454, 'space': 455, 'cup': 456, 'highlight': 457, 'fame': 458, 'reconstruct': 459, 'secret': 460, 'small': 461, 'town': 462, 'profil': 463, 'sever': 464, 'navig': 465, 'pass': 466, 'island': 467, 'book': 468, 'frank': 469, 'produc': 470, 'suffer': 471, 'travel': 472, 'doctor': 473, 'surviv': 474, 'sport': 475, 'candid': 476, 'biggest': 477, 'compani': 478, 'tale': 479, 'other': 480, 'adult': 481, 'extrem': 482, 'musician': 483, 'jewish': 484, 'protest': 485, 'beyond': 486, 'photograph': 487, 'wave': 488, 'statu': 489, 'legend': 490, 'defin': 491, 'eleph': 492, 'govern': 493, 'driver': 494, 'racial': 495, 'break': 496, 'robert': 497, 'brother': 498, 'influenc': 499, 'ancient': 500, 'realiti': 501, 'entrepreneur': 502, 'farmer': 503, 'founder': 504, '–': 505, 'civilian': 506, 'veteran': 507, 'show': 508, 'recal': 509, 'act': 510, 'shock': 511, 'environment': 512, 'achiev': 513, 'modern': 514, 'anniversari': 515, 'nazi': 516, 'benefit': 517, 'heal': 518, 'left': 519, 'chines': 520, 'clash': 521, 'surround': 522, 'basebal': 523, 'scandal': 524, 'name': 525, 'u.s.': 526, 'unpreced': 527, 'long': 528, 'soccer': 529, 'cancer': 530, 'civil': 531, 'brutal': 532, 'ill': 533, 'roll': 534, 'tv': 535, '2012': 536, 'potenti': 537, 'sens': 538, 'shot': 539, 'histor': 540, 'grow': 541, 'worldwid': 542, 'execut': 543, 'festiv': 544, 'insight': 545, 'well': 546, 'wit': 547, 'studio': 548, 'test': 549, 'made': 550, 'master': 551, 'british': 552, 'case': 553, 'access': 554, 'jone': 555, 'campaign': 556, 'epic': 557, 'patient': 558, 'evid': 559, 'like': 560, 'mountain': 561, 'remark': 562, 'popular': 563, 'convict': 564, 'ride': 565, 'soldier': 566, 'wife': 567, 'food': 568, 'part': 569, 'teenag': 570, 'oper': 571, 'dramat': 572, 'daredevil': 573, 'form': 574, 'result': 575, 'blend': 576, 'classic': 577, 'exist': 578, 'dare': 579, 'evolv': 580, 'organ': 581}🍿️Comment: - In this dictionary, each word corresponds to an unique number.
Make a corpus
# Make a corpus.
corpus = [dictionary.doc2bow(text) for text in Docu_stemmed]Establish the LDA model to extract keywords
# Train the lda model based on the dictionary and the corpus.
ldamodel = gensim.models.ldamodel.LdaModel(corpus,
num_topics=1,
id2word = dictionary,
passes=5,
random_state=1)Output
ldamodel.show_topics(num_topics=1)[(0,
'0.039*"documentari" + 0.030*"\'s" + 0.012*"life" + 0.010*"world" + 0.010*"explor" + 0.010*"follow" + 0.009*"``" + 0.009*"\'\'" + 0.009*"film" + 0.007*"stori"')]🍿Comment: - The number in front of each word is measured based on the appearing frequency of the word in the document, and can be explained as the recommendation rate to choose the word as the topic word.
- Some of the words such as “documentary”, “explore”, and “world” accurately reflect the content of this category, which proves the feasibility of this task. - There are many punctuations and uninformative words involved in this list, so the next step is to add these strings to our stop words list to remove them from the dictionary.
Modify the stop words list
myStopWords.extend(["'s","'","·","``",'"','—'])Repeat the steps above
# Make an interactive visualization to reveal the predicted tags for each category.
Desc = []
for i in DescByTypes[19]:
Desc.append([w for w in word_tokenize(i.lower()) if w not in myStopWords])
p_stemmer = PorterStemmer()
Desc_stemmed = []
for i in Desc:
Desc_stemmed.append([p_stemmer.stem(w) for w in i])
dictionary = corpora.Dictionary(Desc_stemmed)
dictionary.filter_extremes(no_below=5, no_above=0.5)
corpus = [dictionary.doc2bow(text) for text in Desc_stemmed]
ldamodel = gensim.models.ldamodel.LdaModel(corpus,
num_topics=1,
id2word = dictionary,
passes=5,
random_state=1)
fig,ax = plt.subplots()
x = []
y = []
count = 0
for i in re.split(re.escape(' + ') + '|' + re.escape('*'), ldamodel.print_topics(num_topics=1, num_words=20)[0][1]):
if count % 2 == 0:
y.insert(0,float(i))
else:
x.insert(0,i)
count += 1
ax.barh(x,y,height=0.5)
ax.set_title(categories[19])
plt.tight_layout()
plt.show()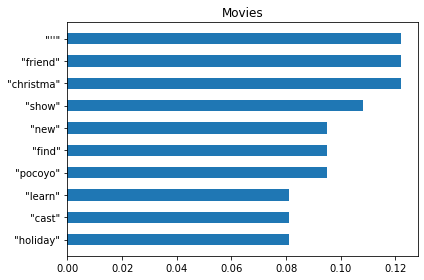
🍿Comments: - The tag words in most categories can accurately reflect the content of the movies invovled in that category, such as “gay”, “love” and “teen” for LGBTQ movies, “murder”, “mystery”, “secret” and “killer” for Thrillers and “team”, “player”, “soccer” and “champion” for sports movies. - By adding those punctuations into myStopWords, there are mostly meaningful words in the graphs. - The “Movies” category that was mentioned before might be some movies about holidays, because of the keywords “friend”, “christma” and “holiday” in the chart.
Visualize the output with wordcloud graph

🍿Comments: - The wordcloud graph visualizes the outcome to a more readable form. Specifically, the size of the words appeared in the graph is aligned with their appearing frequency in the document. - Though there are still several meaningless marks and some of the words are not closely related to the category, there are a bunch of useful words that can generalize the movie category.
🌟A Little Idea: After I’ve done this, it occurs to me an interesting game, which is to use mainly the words provided in the graph to form a sentence related to that category. For instance, we form a sentence related to Documentaries with the words in this graph——“Documentaries are footages about people exploring the world and telling their stories”.
Conclusion
The project has successfully extracted tags from the corpus of a category of movies and has made the outcome visualized. Besides, the result manifests the feasibility to extract keywords from a set of short paragraphs that share some common features, so the methodology might be useful in the future to extract keywords from a set of comments with similarity in the topic and the sentiment.
Movie tags extraction is a promising way to increase the popularity of underestimated movies, and enables more people to enjoy the fun of watching a film that fits their appetites in the holiday. With the rapid development of data science, I believe that in the near future, not only the movies, but also the classic novel, the operas and all other forms of art will be classified and stored in a more fine-grained way, which will make it easier for people to study on them, and dig out more interesting points about them.
If you have any feedbacks or suggestions on how to improve my work, please let me know in the comments.
Thank you!